喜欢1次
队伍编号:CICC3280 团队名称:芯新星队
接上文对wallace树的研究分析,本文主要讲解基4 Booth和wallace数高性能乘法器的设计,同时针对实际情况进行了些许优化。
针对e203的应用场景,本队考虑了其架构修改所要注意的问题,首先是性能和资源的平衡问题:由于Booth算法得出的多个部分和需要相加,尽管基4 Booth算法已经将部分和的数量减少了近一半,但是十几个部分和的加法运算仍将耗费大量的资源,且多级逻辑电路存在不可避免的延迟。
E203将加法操作分为多个周期,每次只对一对部分和进行计算,以便复用同一套硬件资源,以性能换资源。因此提升性能的方法就是增加每个周期计算的部分和数量。当然,这会不可避免地增加逻辑门的延迟。为了找出最佳的方案,本队准备了多种不同程度的性能提升方案,包括4周期、2周期、单周期以及若单周期延迟过大时计划采取的流水线模式。
最终经过测试,本队发现单周期的乘法器是一个很好的选择。在将性能尽可能提高的同时,门电路延迟也完全满足要求。甚至在本队尝试将频率提升至32MHz(原E203的2倍)时,该乘法器,包括后文将提到的改进后的除法器依然可以完美地工作。
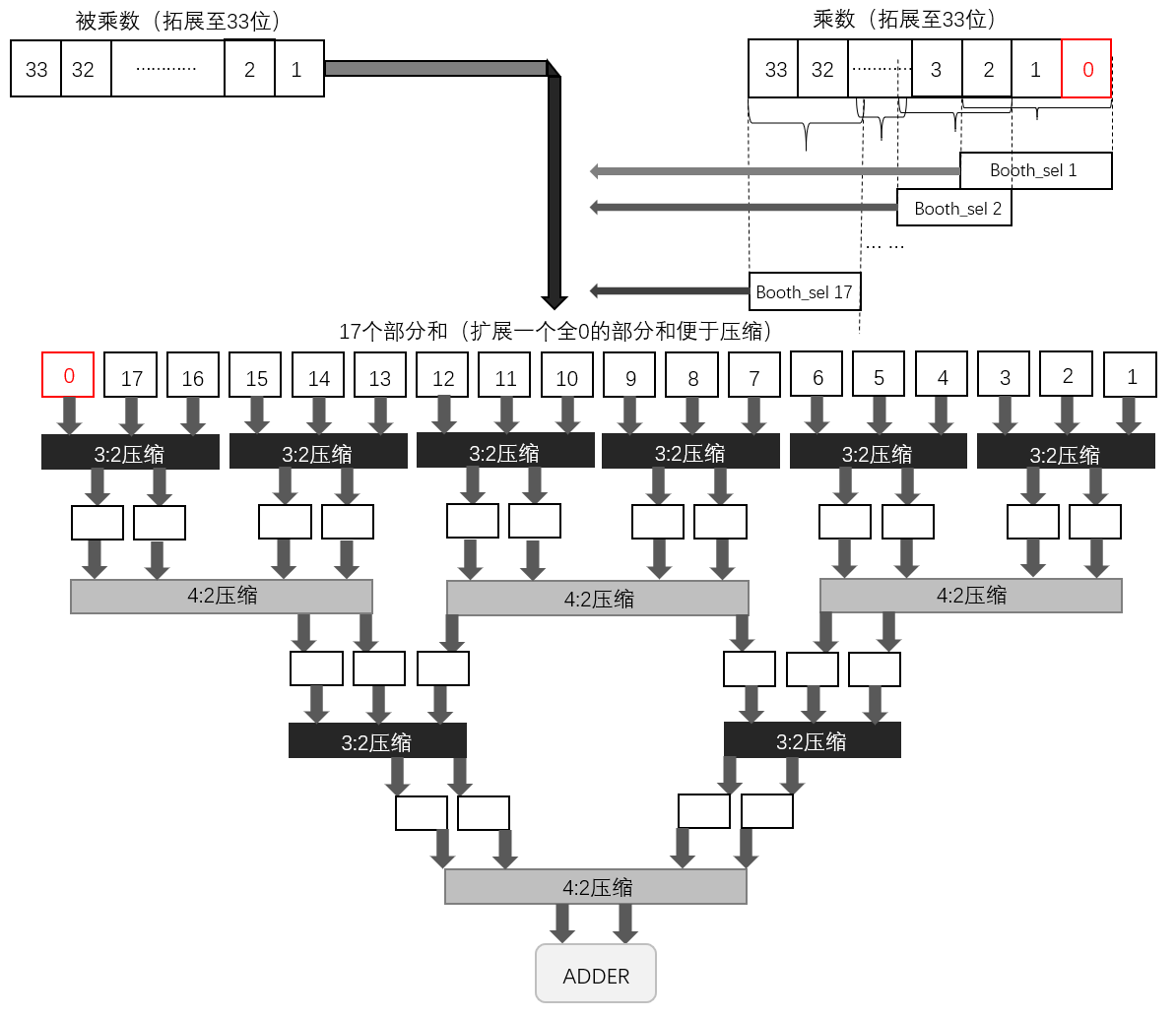
乘法器具体结构如下图所示:
wire [36:0] op_00 = ({37{booth_sel_00[0]}} & {1'b1,36'b0})
| ({37{booth_sel_00[1]}} & {~mul_rs2[32],mul_rs2[32],mul_rs2[32],mul_rs2,1'b0})
| ({37{booth_sel_00[2]}} & {~rs_2_2[33],rs_2_2[33],rs_2_2[33],rs_2_2})
| ({37{booth_sel_00[3]}} & {~mul_rs2[32],mul_rs2[32],mul_rs2[32],mul_rs2[32],mul_rs2})
| ({37{booth_sel_00[4]}} & {~rs_2_1[33],rs_2_1[33],rs_2_1[33],rs_2_1}) ;
wire [35:0] op_01 = ({36{booth_sel_01[0]}} & {2'b11,34'b0})
| ({36{booth_sel_01[1]}} & {1'b1,~mul_rs2[32],mul_rs2,1'b0})
| ({36{booth_sel_01[2]}} & {1'b1,~rs_2_2[33],rs_2_2})
| ({36{booth_sel_01[3]}} & {1'b1,~mul_rs2[32],mul_rs2[32],mul_rs2})
| ({36{booth_sel_01[4]}} & {1'b1,~rs_2_1[33],rs_2_1});
wire [34:0] op_16 = ({35{booth_sel_16[0]}} & {1'b1,34'b0})
| ({35{booth_sel_16[1]}} & {mul_rs2[32],mul_rs2,1'b0})
| ({35{booth_sel_16[2]}} & {rs_2_2[33],rs_2_2})
| ({35{booth_sel_16[3]}} & {mul_rs2[32],mul_rs2[32],mul_rs2})
| ({35{booth_sel_16[4]}} & {rs_2_1[33],rs_2_1});
| ({36{booth_sel_02[4]}} & {1'b1,~rs_2_1[33],rs_2_1});
这段代码的作用是计算部分积,使用了类似于多路选择器结构的控制电路,通过得出的Booth操作来选择部分和的值。
值得一提的是,本队采用符号位扩展的方法,针对负数的补码做了一定的优化。在使用补码的情况下,若部分和为负数,则需要在部分和的前方全部补上“1”,这会导致低位部分和的全部高位都需要参与运算,需要将所有的压缩器都设计为64位,这显然是不合适的。而进行符号位扩展即可完美解决这一问题。
经过Vivado仿真后,乘法器的资源消耗如图七所示。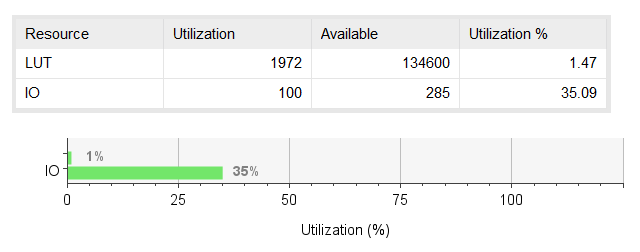
具体的符号位扩展方法和项目代码会在比赛结束之后考虑开源在github平台